Linear Regression#
TODO
Regression Model#
TODO
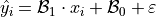
Where the term  is a normally distributed error term centered around 0 with standard deviation equal to the mean squared error of the model,
is a normally distributed error term centered around 0 with standard deviation equal to the mean squared error of the model,
TODO
Mean Squared Error#
The term 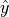 is not the observed value of
is not the observed value of 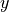 in the bivariate sample of data that was used to calibrate the model. It is the predicted value of given the observed value of
in the bivariate sample of data that was used to calibrate the model. It is the predicted value of given the observed value of 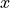 . This is an extremely important point when talking about regression. The model equation is a prediction, and the prediction is not exact. Each predicted value of , , will deviate from the observed value of . The deviation, if the model is a good fit, should be normally distributed around 0.
. This is an extremely important point when talking about regression. The model equation is a prediction, and the prediction is not exact. Each predicted value of , , will deviate from the observed value of . The deviation, if the model is a good fit, should be normally distributed around 0.
TODO
SSE: Sum Squared Error#
TODO
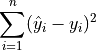
TODO
MSE: Mean Squared Error#
TODO
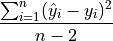
TODO
Model Coefficients#
The regression model coefficients can be estimated by finding the values of 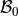 and
and 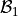 that minimize the MSE of the model.
that minimize the MSE of the model.
In other words,
TODO: example. plug in various values of coefficients and demonstrate the MSE varies. Show there is a value that produces a minimum.
Note
In order to derive an algebraic expression for the coefficients, differential calculus is required. If you want an extra credit assignment related to this, talk to me outside of class.
TODO
TODO
Line of Best Fit#
TODO