Normal Distribution#
The Normal Distribution is the foundation of inferential statistics. The Normal Distribution represents the ideal population distribution for a sample that is approximately normal.
Normality#
Introduction#
Normality arises when observations being randomly drawn from a Population are independent and identically distributed. In other words, if a series of experiments are performed where each experiment is the same as the last in every respect, then the outcomes of all the experiments taken together should be approximately normal.
Important
Independence and Identically Distributed are mathematical concepts with precise defintions. We will talk more about them in the section on probability
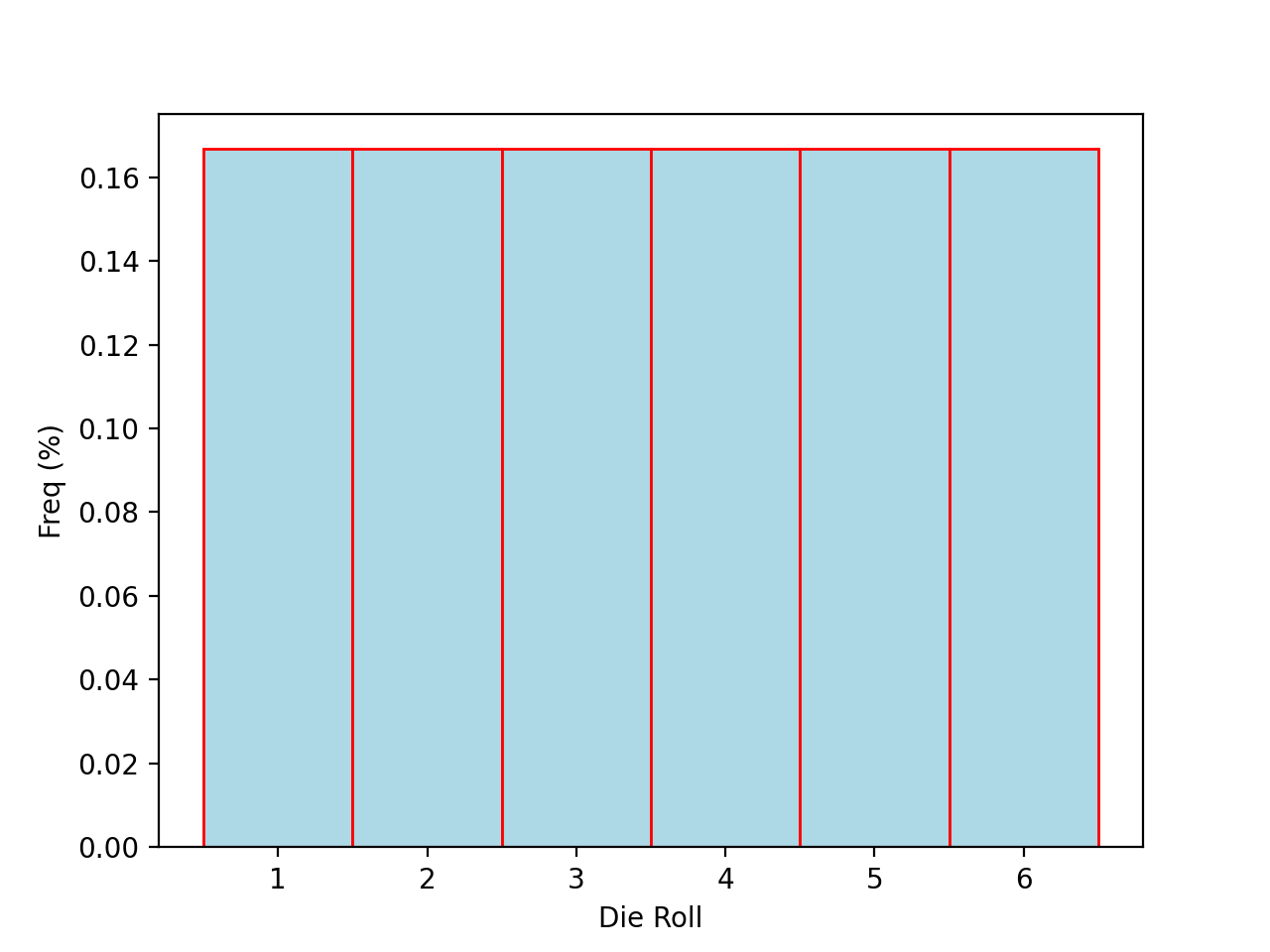
In order to explain the origin of normality, it is instructive to consider a simple example. Consider the experiment of rolling a single die. Think about what the ideal relative frequency distribution for this experiment should look like. A die has six sides and each one is equally likely. If we let 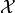 represent the outcome a rolling a single die, we can express the relation of all outcomes being equally likely with the following equation,
represent the outcome a rolling a single die, we can express the relation of all outcomes being equally likely with the following equation,
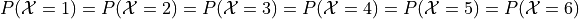
To say the same thing in a different way, the probability of all outcomes should be the same,
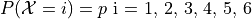
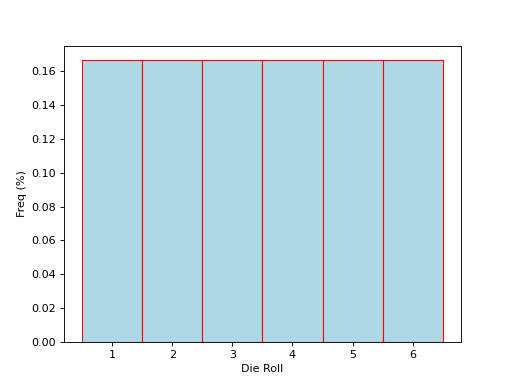
The ideal histogram (in other words, the distribution of the population) would look perfectly uniform,
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
Consider now the experiment of rolling 30 die. The relative frequency of each outcome in the ideal distribution will not change, since the new die being rolled consist of the same outcomes as the original die; Outcomes are added to the experiment in the same proportion.
Take this experiment of rolling 30 die and repeat
TODO
A departure from normality can suggest several things:
The selection process was not random.
The observations are not independent.
The observations are not being drawn from the exact same population.
Normal Calculations#
When we calculate Normal probabilities, we usually work with Z distributions, where each observation 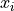 has been converted into a Z Score
has been converted into a Z Score 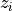 ,
,
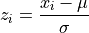
The reason for this transformation is easily understood by recalling the data transformation theorems that state the mean of a Z distribution will always be 0 and the standard deviation of a Z distribution will always be 1.
If an observation drawn from a population follows a Normal distribution with mean 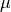 and standard deviation
and standard deviation 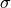 , we write,
, we write,
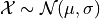
Then, the corresponding Z distribution can be written,
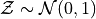
TODO
Cumulative Distribution Function#
The cumulative distribution function (CDF) for the Normal distribution is an extremely important function in mathematics. Symbolically, it is written,
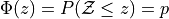
This function represents the area under the density curve to the left of the point  . In other words, This function tells us the percentage
. In other words, This function tells us the percentage 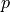 of the Standard Normal distribution that is less than or equal to the point . To put it yet another way, it tells us what percentage of the original Normal distribution is less than or equal to standard deviations away from the mean.
of the Standard Normal distribution that is less than or equal to the point . To put it yet another way, it tells us what percentage of the original Normal distribution is less than or equal to standard deviations away from the mean.
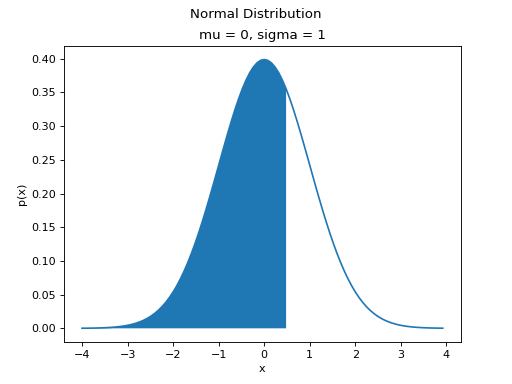
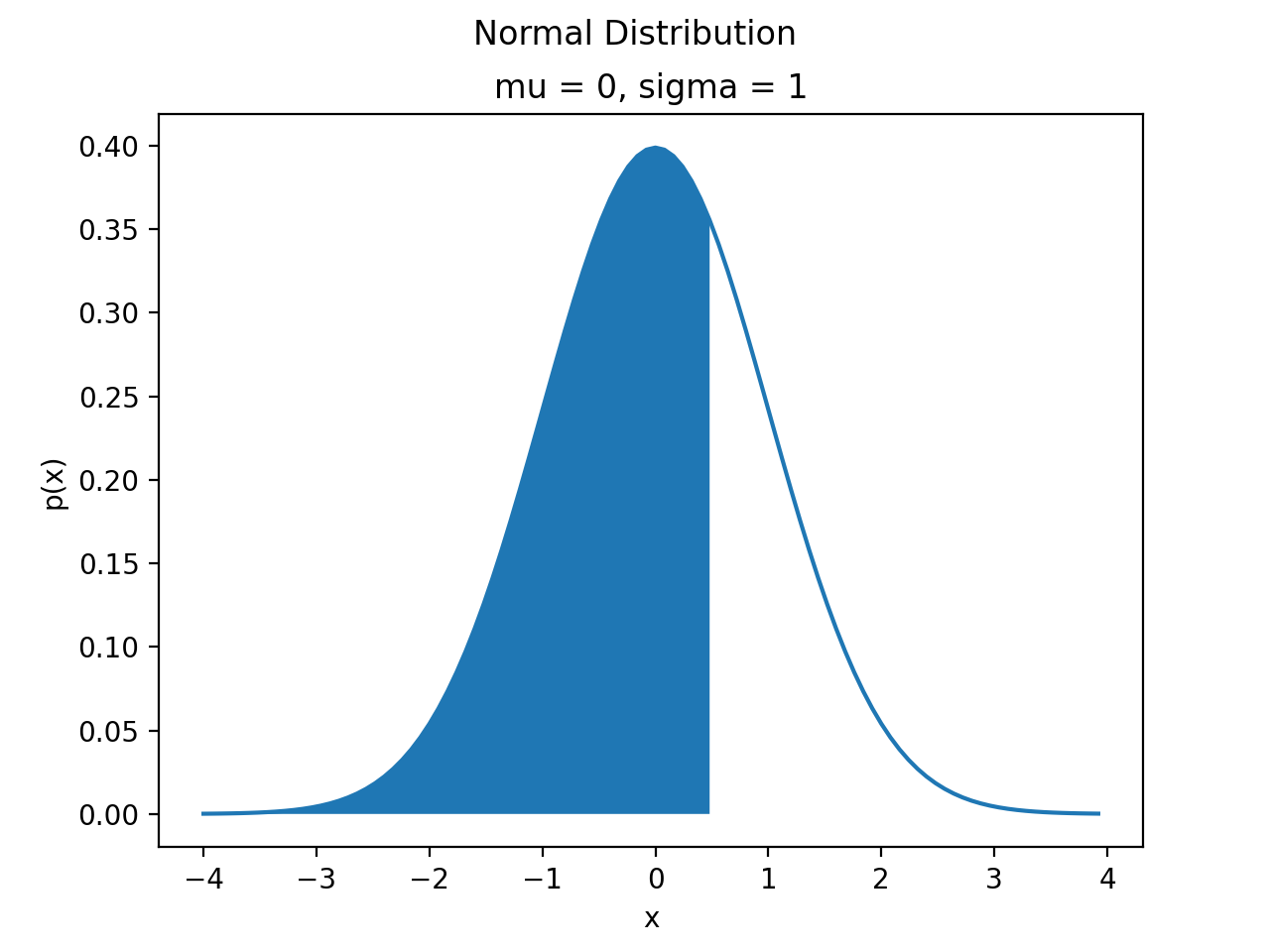
Graphically, we can think of the Normal CDF at a point, 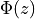 as representing the shaded area to the left of . For example, the quantity
as representing the shaded area to the left of . For example, the quantity 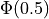 can be visualized as the shaded region under the density curve,
can be visualized as the shaded region under the density curve,
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
Inverse Cumulative Distribution Function#
Every well-behaved function has an inverse. The CDF of the Normal Distribution is no different. The inverse CDF is denoted,
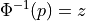
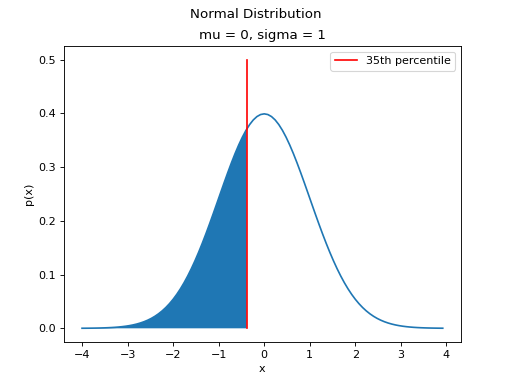
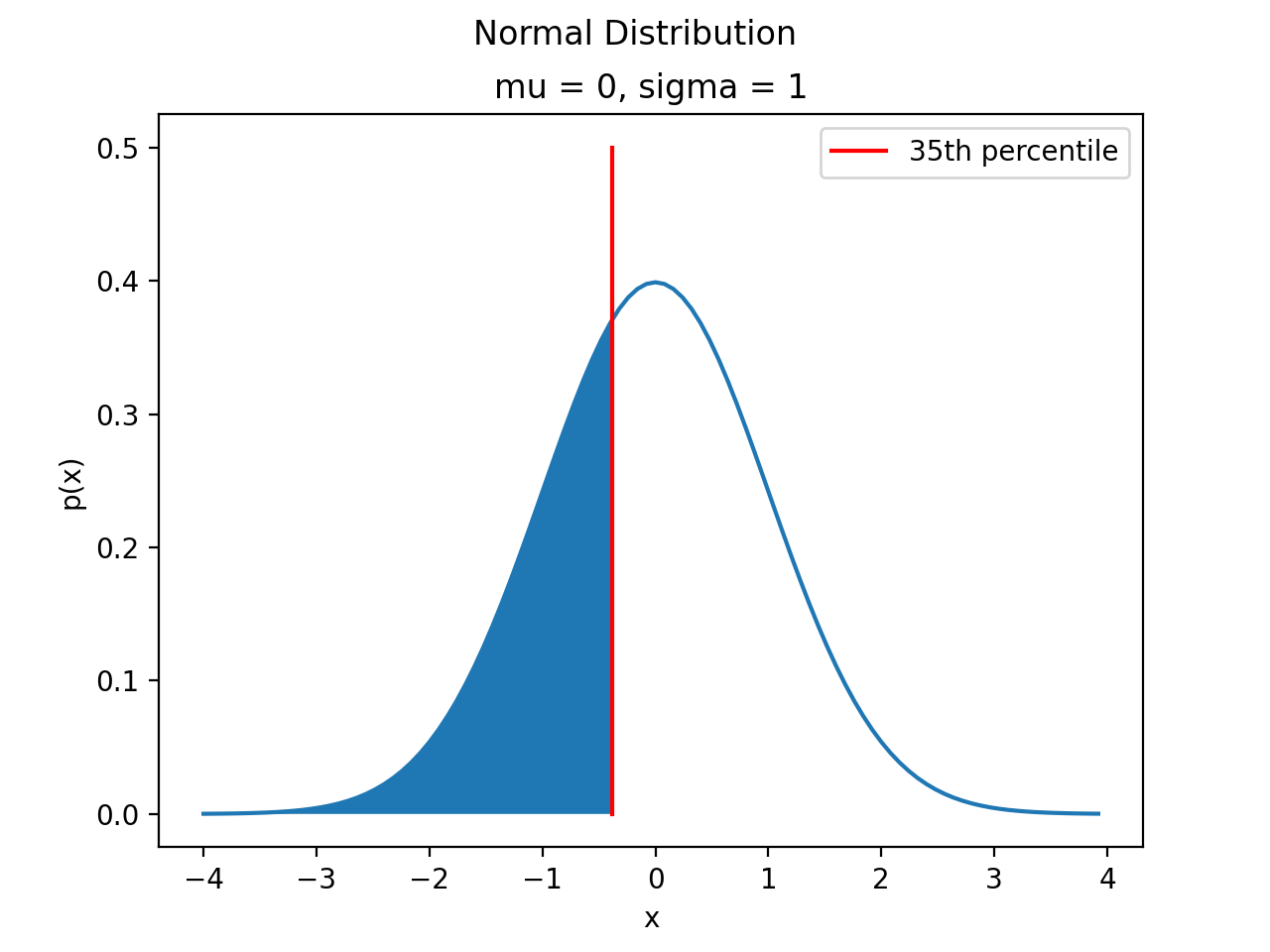
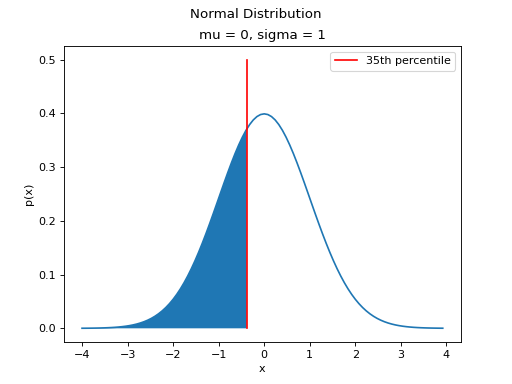
The CDF tells us, given a value of , what percent of the distribution is below . The inverse CDF, on the other hand, tells us, given a value of , what observation corresponds to that percentile. It is the point on the Normal density curve such that the shaded area below is equal to .
As an example, if we were interested in the 35 th percentile of the Standard Normal distribution, the inverse CDF would tell us the point such that 35% of the distribution is less than or equal to that point, i.e. the point where the area to the left of the is 35%.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
Symmetry#
TODO
Z-Tables#
These days we have calculators that can perform almost any calculation you can imagine, but back in the old days, aspiring mathematicians needed to be familiar with tables. Many functions in trigonometry and algebra do not have closed form algorithms for their exact calculation, so their values must be looked up in a table.
For example, 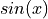 is a trigonometric quantity defined as the ratio of sides in a right triangle. It is, in general, impossible to calculate the exact value of for an arbitrary
is a trigonometric quantity defined as the ratio of sides in a right triangle. It is, in general, impossible to calculate the exact value of for an arbitrary 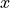 without more advanced techniques introduced in Calculus. For this reason, before the advent of modern computing, values of sin were tabulated in tables like the following,
without more advanced techniques introduced in Calculus. For this reason, before the advent of modern computing, values of sin were tabulated in tables like the following,
(TODO: insert picture)
Similarly, the Standard Normal distribution is defined by a density curve whose area is not easily calculated without a substantial amount of math-power (like horse-power, but with math). In order to aid in calculations, statisticians of the past tabulated the values of the Standard Normal and devised a way of representing the CDF of the Standard Values through a two-way table,
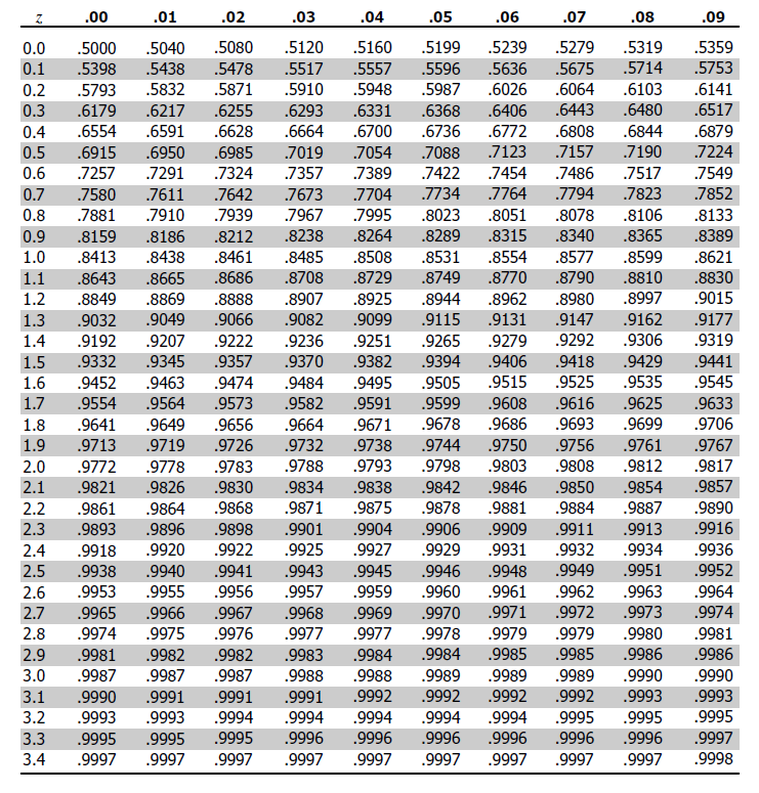
This table can answers questions like,
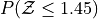
First, we find the row that corresponds to the two leading digits, 1.4.
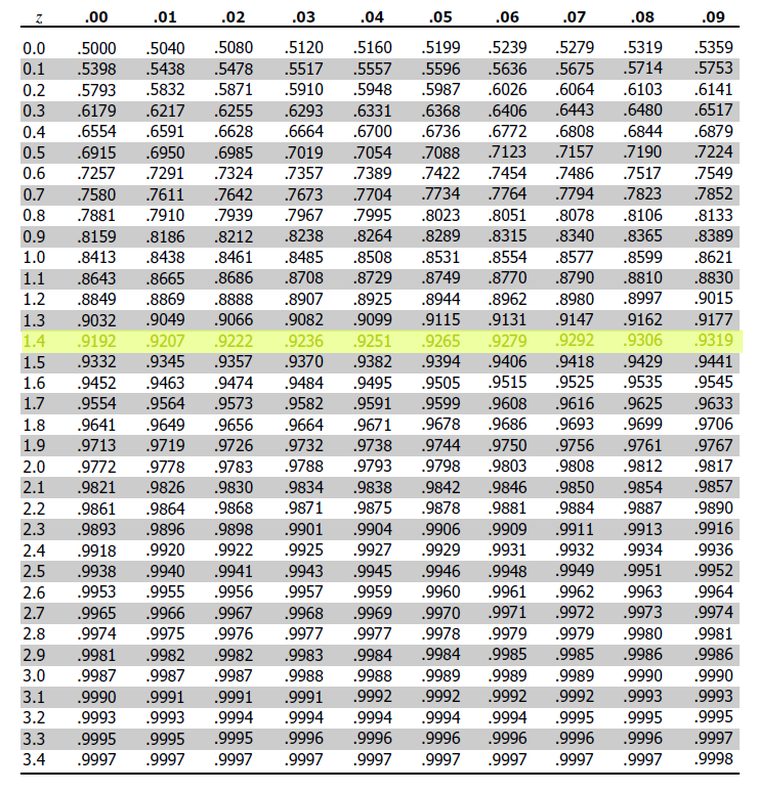
Then, we find the column that corresonds to the last decimal spot, 0.05.
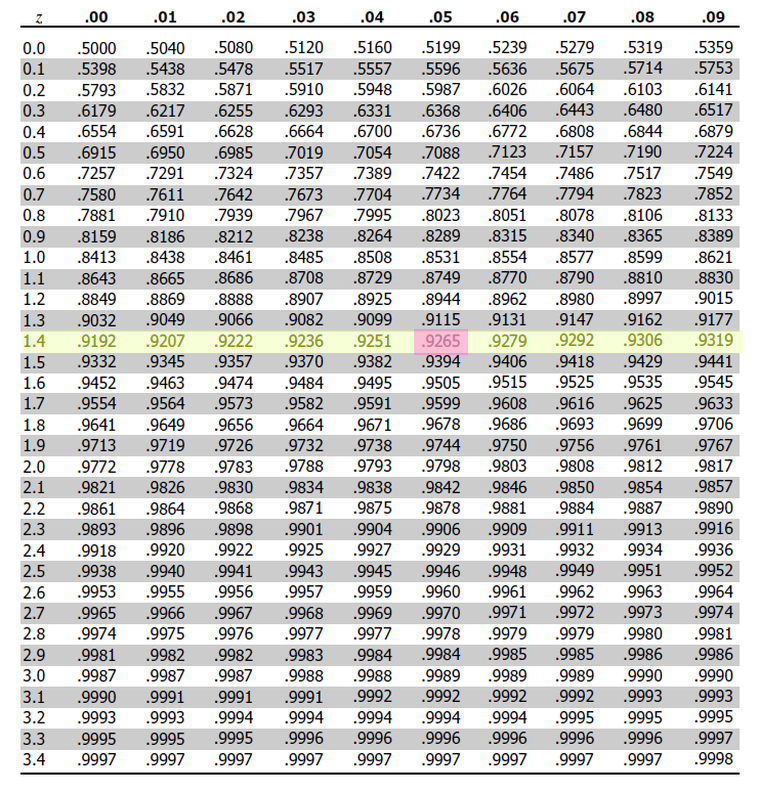
This tells us that 92.65% of the Standard Normal distribution has a distance less than or equal to 1.45 standard deviations from the mean.
Empirical Rule#
TODO
The Empirical Rule can be visualized through the area underneath the Normal curve,
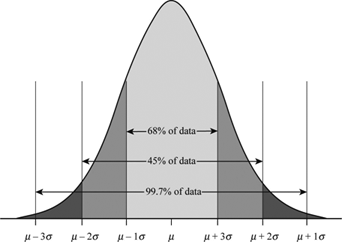
TODO
Parameters#
Mean#
TODO
Varying the Mean Parameter#
TODO
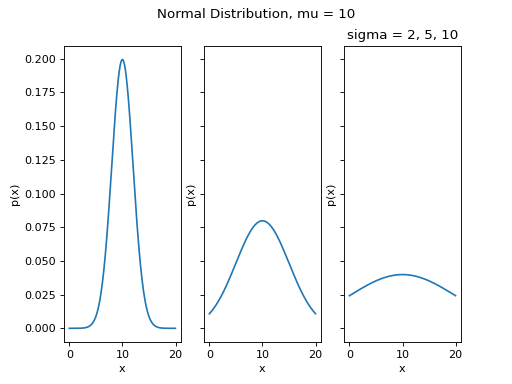
Standard Deviation#
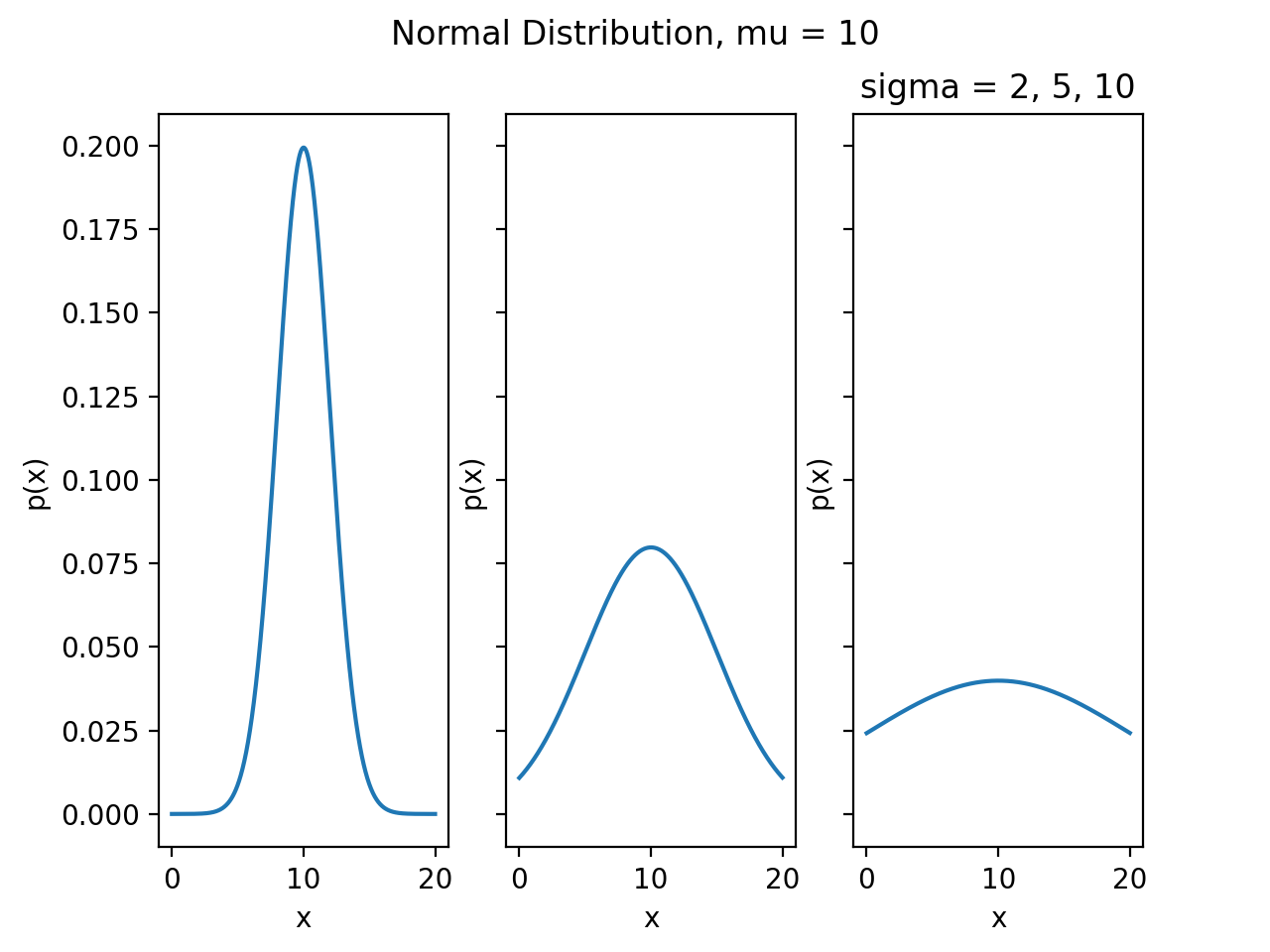
Varying the Standard Deviation Parameter#
By changing the Standard Deviation, the shape of the distribution changes. As the Standard Deviation increase, the graph spreads out. This is because Standard Deviation is a measure of variation. In other words, Standard Deviation quantifies how the distribution is spread out along the x-axis.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
Summary#
To summarize,
Assessing Normality#
TODO
QQ Plots#
A common technique for assessing the normality of a sample distribution is to generate a Quantile-Quantile Plot, or QQ Plot for short. QQ plots provide a visual representation of a sample’s normality by plotting the percentiles of a sample distribution against the percentiles of the theoretical Normal Distribution.
The exact steps for generating a QQ plot are given below,
Find the :ref`order statistics <order_statistics>` of the distribution. In other words, sort the sample in ascending order.
Note
Step 1 is equivalent to finding the percentiles of the sample distribution.
Standarize the sorted sample, i.e. find each observation’s Z Score.
Find the theoretical percentiles from the Standard Normal Distribution for each ordered observation.
Plot the actual percentiles versus the theoretical percentiles in the x-y plane.
Consider the following simplified example. Let the sample 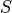 be given by,
be given by,
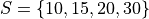
The sample statistics for this distribution are given by,
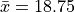
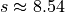
Standardizing each observation and rounding to the second decimal spot,
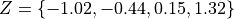
Then, we construct the theoretical percentiles of the Standard Normal distribution for a sample of size 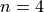 . To do so, we take the inverse CDF of the sample percentile,
. To do so, we take the inverse CDF of the sample percentile,
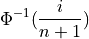
For 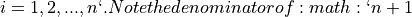 . If it is surprising the denominator is
. If it is surprising the denominator is 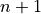 instead of n, read through the order statistics section. There are n observations, but these values divide the number line into n + 1 intervals.
instead of n, read through the order statistics section. There are n observations, but these values divide the number line into n + 1 intervals.
In this example, we would find,
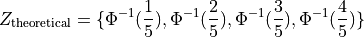
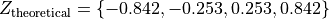
After constructing the theoretical percentiles, we create a scatter plot using the order paired,
( actual percentile, theoretical percentiles )
If the sample distribution is Normal, we should observe a linear relationship between the x-value and the y-value of this scatter plot. The following plot is the QQ plot summarizes the normality of this example,
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
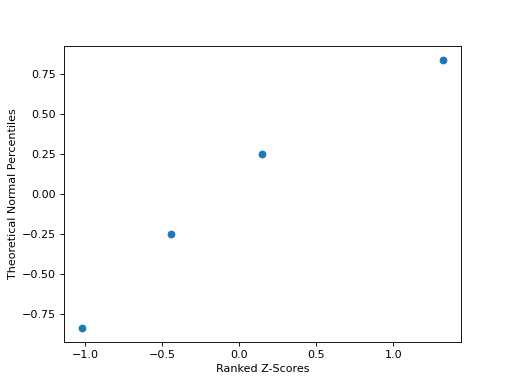
We notice an approximately linear relationship between the observed percentiles and the theoretical percentile, and thus we conclude there is no evidence to suggest the distribution is not normal.
Important
The phrasing here is important! We have not shown the distribution is Normal. We have only provided evidence to contradict the claim the distribution is not Normal. In other words, we have demonstrated the falsity of a negative claim; we have not demonstrated the truth of a postive claim.
Relation To Other Distributions#
The Normal Distribution is deeply connected with many different areas of mathematics. It pops up everywhere, from quantum mechanics to finance. The reach of the normal distribution is far and wide.
Normal As An Approximation of the Binomial#
TODO
Poisson As An Approximation of the Normal#
TODO