Random Variables#
Many things in life are uncertain. Nevertheless, uncertainy doesn’t equate to unpredictability. Even though events may be uncertain, we can still make predictions about their outcome based on our knowledge of the sample space. Before we can do that, we need to talk about random variables and how they can be used to model processes in the real world.
Definition#
The following sentences all say the same thing in slightly different ways.
A random variable
is an uncertain quantity.
A random variable
A random variable
Example #1-A
A friend flips a fair, two-sided coin. If it lands on heads, he will pay you five dollars. If it lands on tails, you have to pay him five dollars.
Solution #1-A
The sample space for this simple game is given by,
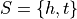
The amount of money you win or lose is a random variable that depends on the outcome of the coin flip, i.e. whether the event of 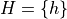 or the event
or the event 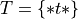 from the sample space occurs. Using this information, we can define the random variable for the amount of money won or lost playing this game as follows,
from the sample space occurs. Using this information, we can define the random variable for the amount of money won or lost playing this game as follows,
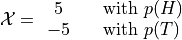
We can use a table to visualize the outcomes of this random variable and their associated probabilities,
x |
P(X = x) |
5 |
P(H) = 0.5 |
-5 |
P(T) = 0.5 |
Notice this is similar in form and function to a frequency distribution.
Example #1-B
Suppose you own a car that gets 30 miles per gallon of gasoline. Due to your commute, you drive your car approximately 120 miles every week. Describe the cost of operating your car as a random variable measured in dollars.
Solution #1-B
Your weekly cost of keeping your tank full is given by the expression
(Weekly Cost of Gas) = (Price per Gallon of Gasoline)
(Gallons Used)
If we assume you drive the exactly same amount every week, the second term on the right hand side of the expression can be written as,
(Gallons Used) =
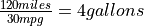
The price per gallon of gasoline, however, is an uncertain quantity; it depends on many extranenous factors, such as political conditions, shipping costs, taxes and tariffs, weather and climate, etc. Because of this, the price changes from day to day.
The uncertainty in the price of gasoline becomes uncertainty in the weekly cost of driving your car. Therefore, we can model the weekly cost of gas as a random variable,
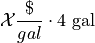
where is the price of gasoline measured in dollars per gallon.
Random Variable or Random Function?#
A random variable is not very well named.
Reminder
In case you have forgotten, statisticians are very bad at naming things.
A more suitable name would be random function. In this section, the reason for this will be explored. We will examine the connection between random variables and functions.
Review of Functions#
Recall the concept of a function from your other mathematics classes. You probably remember a definition along the lines, “A function 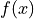 receives an input x and assigns to it a value y.” This definition has served you in your mathematics career up to this point, but it will no longer suffice. This is not precisely what a function is, though it is a close approximation. In order to understand what a random variable is, the concept of a function must be extended and enlarged to encompass a larger set of ideas (pun intended).
receives an input x and assigns to it a value y.” This definition has served you in your mathematics career up to this point, but it will no longer suffice. This is not precisely what a function is, though it is a close approximation. In order to understand what a random variable is, the concept of a function must be extended and enlarged to encompass a larger set of ideas (pun intended).
When the concept of functions is first taught, students are encouraged to treat a function as an algebraic expression, such as 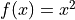 . It’s an algebraic thing that you plug numbers into and out of which you get numbers, which may or may not be the same numbers that were inputted (consider the output of
. It’s an algebraic thing that you plug numbers into and out of which you get numbers, which may or may not be the same numbers that were inputted (consider the output of 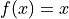 versus ; what is the difference between the set of things output by each of these function?). When f(x)=x^2, we put x = 5 and get f(5) = 25, which describes an ordered pair in the Cartesian plane,
versus ; what is the difference between the set of things output by each of these function?). When f(x)=x^2, we put x = 5 and get f(5) = 25, which describes an ordered pair in the Cartesian plane, 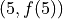 . Students are told about the domain and range; The set of all values that are input into a function is called the domain. Likewise, the set of all values that is output by the function is called the range. You probably remember seeing a diagram to help you visualize this idea and it probably looked like this,
. Students are told about the domain and range; The set of all values that are input into a function is called the domain. Likewise, the set of all values that is output by the function is called the range. You probably remember seeing a diagram to help you visualize this idea and it probably looked like this,
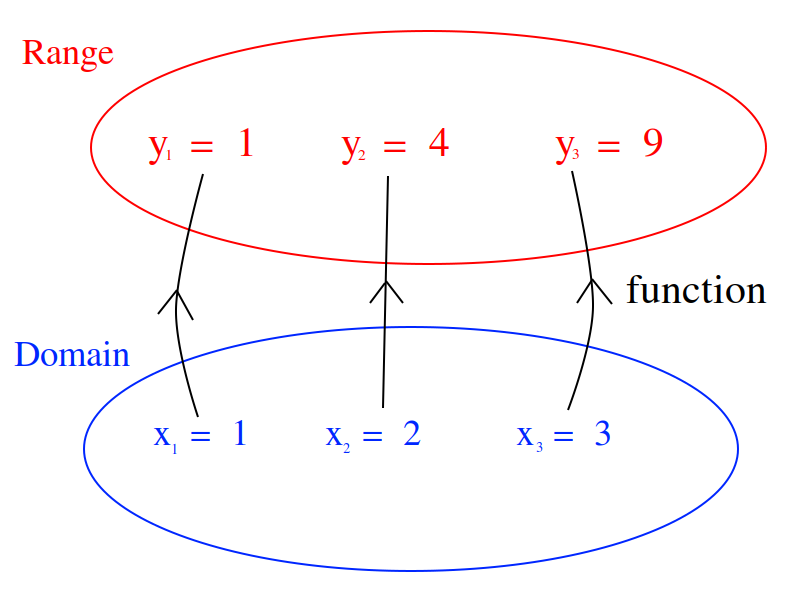
And then you studied various types of algebraic functions, such as logs and sines. You learned about the joy of factoring and finding roots. You plotted curves and found inflection points. Life was idyllic; It seemed as though nothing could ever shatter the peace and serenity you were blessed with amidst the glory of algebra. However, this is not the whole story.
Extension of The Concept of a Function#
The concept of a function underwent a radical change in the early 20 th century as set theory was developed by people with names like Guiseppe Peano and Ernst Zermelo to formalize the foundation of mathematics and make it so rigorous it was beyond reproach. To see why the notion of a function had to be extended, consider the following propositions,
The set of all unicorns has zero elements.
The set of all humans has seven billion elements.
The set of all natural numbers is infinite.
The set of all prime numbers is infinite.
These statements could be translated into set theoretic symbols in the following way,
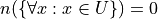
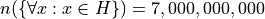
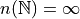
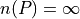
If the specifics were abstracted away, this would lead to an expression that looks like,
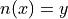
In each case, the cardinality of something is being asserted. In other words, a value is being assigned to an input, but what exactly is the input? Each proposition is asserting a property of an entire set; this suggests the constraint that functions are numbers be relaxed so that we may input sets into funtions.
Put in the parlance of modern mathematics, a function maps a value to a given set. The set of all values that are mapped is likewise a set of things. This leds to the idea of a function as a map between sets. A function takes elements from one set and maps them to the elements of another set. This slight change in the way functions are talked about leads to a revision of the diagram given at the beginning of this section,
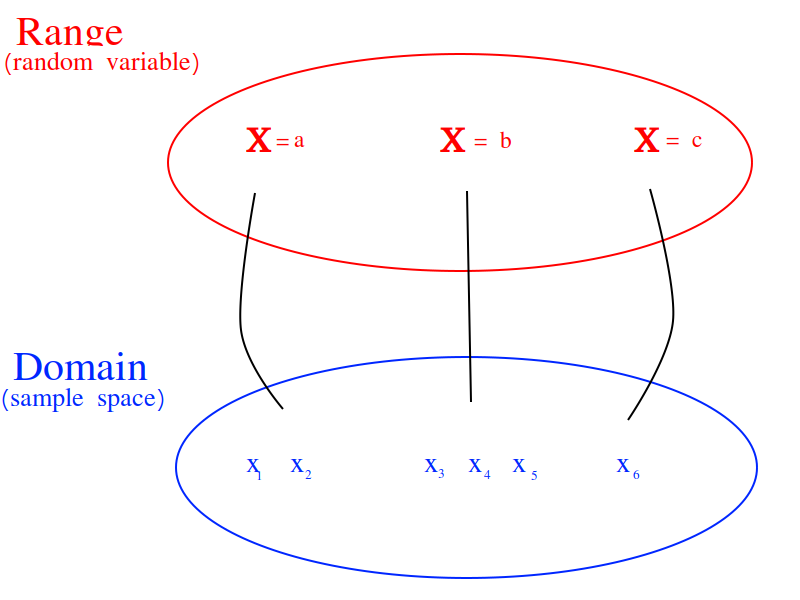
This suggests we view random variables as functions of the outcomes in sample space,
This is getting closer to the truth. However, this picture is not yet complete; it doesn’t include probability. The outcomes in the sample space are uncertain.
Random Variables and Events#
The outcomes in a event determine the value of the random variable in the same way the values inputted into a function determine the output of the function. However, the input to a random variable is uncertain, therefore the output is likewise uncertain. The probability of an event occuring in the sample space is transferred, through the outcomes that determine the random variable, into the probability of a random variable assuming a particular value. An event (set) of outcomes in the sample space becomes an assignment of a particular value to a random variable,
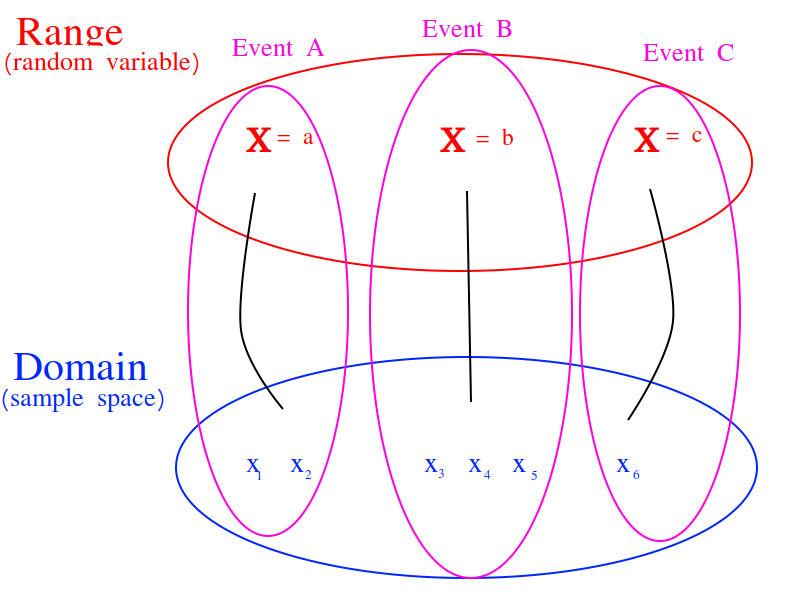
A random variable shows how events from the sample space (the domain) are transformed into events of the random variable (the range).
Properties#
Probability Density Function#
The density function should be familiar. We have already encountered its statistical analogue, Frequency. The probability density of a random variable at a certain value is analogous to the frequency of an observation in a sample of data.
TODO
Cumulative Distribution Function#
TODO
Expectation#
TODO
TODO
The expectation of a Random Variable is the weighted sum of its outcome. The weight of each outcome is exactly the probability of that outcome occuring.
TODO
Here the subject matter is sample spaces and probability, but the current discussion bares a striking similarity of the discussion of the sample_mean. The reader may wonder if there is a connection between the expectation of a random variable and the mean of a sample randomly drawn from the same underlying population (if the reader does not wonder this, this sentence is meant to elicit said wonder, so start wondering). In fact, the formulae for expectations and sample means share a connection through the law_of_large_numbers.
Recall the formula for the sample mean is written,
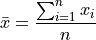
However, when it is written like this, the connection to expectations is not so obvious. The index of this summation, i, is taken over the individual observations, rather than the unique observations. We may rewrite this formula, with the concept of Relative Frequency, 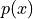 ,
,
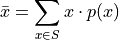
The connection is now more apparent. In the limit, as the number of observations in the sample S approaches the number of individuals in the population, the relative frequency of an observation becomes the probability of the individual occuring in the population.
TODO
Variance#
TODO
If the additional constraint is added that is discrete, the outer expectation can be expanded and rewritten,
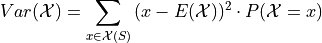
TODO
TODO
Standard Deviation#
TODO
Theorems#
TODO
Scalar Properties#
The results in this section will be used as building blocks to construct complex Random Variables from simple foundations. The following properties of Random Variables state how the expectation of a given is shifted and scaled by a constant factor of a
Linearity of Expectations#
The Scalar Properties detail how the expectation of a Random Variable is modified by a constant value. The results of this section extend this idea to the composition of Random Variables. In other words, the following theorem describes how the expectation of a sum of Random Variables can be decomposed into the expectation of each individual Random Variable in the sum,
TODO
Example #2-C
Suppose you play a game where you roll a die and then flip a coin. If you roll a 6, you win $1. If the coin lands on a head, you win an additional $1. What is the expected value of your winnings?
Solution #2-C
In this example there are two random processes: the amount of money you win from rolling the die and the amount of money you win from flipping the coin. Call the former and call the latter 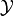 . The quantity of interest in this problem is then given by,
. The quantity of interest in this problem is then given by,
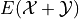
By the linearity of expectations, this can be broken down into the individual expectations,
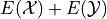
For , note the outcome of winning $1 has a probability of  and the outcome of winning $0 has a probability of
and the outcome of winning $0 has a probability of  . Therefore,
. Therefore,
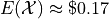
Similary, the expectation of is found by,
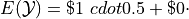
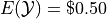
Therefore, the expected value of the winnings in this game is,
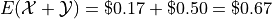
Note
This problem is not so simple without the linearity of expectations! You would need to account for all possible outcomes and find the probability distribution for the sample space!
Variance of a Sum#
TODO